
with parallelization python module "multiprocessing"
In this article, we will see explore how we can generate random arrays of any shape using the method numpy.random.randint() in two phases: one running a single process and a second one with multiprocessing module. We aim here to construct a 2D numpy array of random int.
Random number does NOT mean a different number every time. Random means something that can not be predicted logically
Random arrays can be used for multiple purposes such as algorithm construction, investment strategy backtesting, statistical calculation and many other applications.
1. Generate random arrays with a single process
We want a to impose two conditions for the generated random numbers where:
- A minimum and maximum range for each number in the final output.
- The sum of the elements of one row of the final array should be equal to 1.
We define first the minimum and maximum ranges corresponding to the first condition:
ranges=[[0,99],[0,99],[0,99],[0,99],[0,99]] m=10
The final array should be of shape m x len(ranges)
We initiate the arrays we want to fill later with random numbers:
df_ranges=pd.DataFrame(ranges,columns=['range low','range high']).transpose() arr_ranges_low=df_ranges.values[0] arr_ranges_high=df_ranges.values[1] # l=len(ranges) rands=np.zeros(l) weights=np.zeros((m,l))
For each element, we call numpy.random.randint() between the minimum and maximum ranges. A while condition will be used in order to satisfy the second condition.
for k in range(m):
while rands.sum()!=1000:
rands=np.array([np.random.randint(
arr_ranges_low[i],arr_ranges_high[i]
) for i in range(l)])
if rands.sum()==100:
weights[k]=rands
break
We look for random elements satisfying the first conditions until the second condition is met and then we exit.
We group the previous code into one function rand_weights(ranges,m) and get a random output:
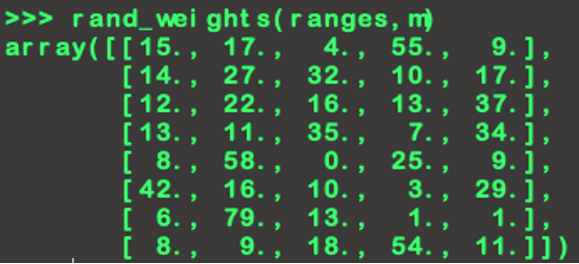
rand_weights can be executed for a very large number of iterations such as 100 000 or more, but the approach can be very consuming regarding memory usage and time optimization. Hence, we can execute it on multiple process using the package multiprocessing.
2. Generate random arrays using multiprocessing
Multiprocessing is package that supports spawning processes using an API similar to the threading module. The multiprocessing package offers both local and remote concurrency, effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads.
for more details, please visit:
A prime example of this is the pool object which gives a convenient means of parallelizing the execution of a function across multiple input values, distributing the input data across processes (data parallelism). The following example demonstrates the common practice of defining such functions in a module so that child processes can successfully import that module.
Since our function rand_weights takes multiple arguments, we will use Multiprocessing method pool.starmap() which accepts a sequence of argument tuples, it then automatically unpacks the arguments from each tuple and passes them to our function.
We can build a function MP_a_func that use pool.starmap() method for any function where:
- Proc is the number of processes we wish to use.
- Chunk is the how we want to partition.
- iterable is the list containing tuples of rand_weights arguments.
def MP_a_func(func,iterable,proc,chunk):
pool=multiprocessing.Pool(processes=proc)
Result=pool.starmap_async(func,iterable,chunksize=chunk)
pool.close()
return Result
We can test our function on a number of iterations n_iter=1000:
iterable=[[ranges,m] for n in range(n_iter)]
if __name__ == '__main__':
results=MP_a_func(rand_weights,iterable,proc,chunk)
MP_a_func returns a list containing 1000 random numpy arrays generated using multiprocessing module in python.
We hope this interactive article from yacodata at www.yacodata.com helped you understand the basics of generating random numbers, so you can use for you proper applications.
If you liked this article and this blog, tell us about it our comment section. We would love to hear your feedback!