
Using API call with python
Imagine you need to build a database of stock fundamentals from various web pages and you want to automate the process. How would you do it without manually going to each website and getting the data?
Well, Beautifulsoup is the answer. This library just makes the process easier and faster with basic python knowledge.
In this article on getting stock fundamentals from Yahoo finance using python Beautifulsoup, you will learn about Beautifulsoup package in brief and see how to extract data from a website with a demonstration.
This article assumes you have a running python environment and know the basics of using python language.
1. Let’s first install Beautifulsoup and requests in our environment
The requests module allows you to send HTTP requests using Python. The HTTP request returns a Response Object with all the response data (content, encoding, status, etc).
pip install beautifulsoup4 pip install requests
Please refer to the following link for a step-by-step installation process:
Now, since you have installed Beautifulsoup in your environment, we can begin by looking for the web page from where we aim to extract stock fundamentals.
Yahoo finance https://finance.yahoo.com delivers free stock quotes, up-to-date news, portfolio management resources, international market data, social interaction and mortgage rates. Let’s choose a company we are interested in for further analysis. For example, Hecla mining which is is a gold, silver and other precious metals mining company based in Coeur d'Alene, Idaho. Hecla Mining Company is the largest primary silver producer in the U.S. – and the oldest NYSE-listed precious metals mining company in North America.
2. Let’s fetch for Hecla mining stock fundamentals in the statistics onglet
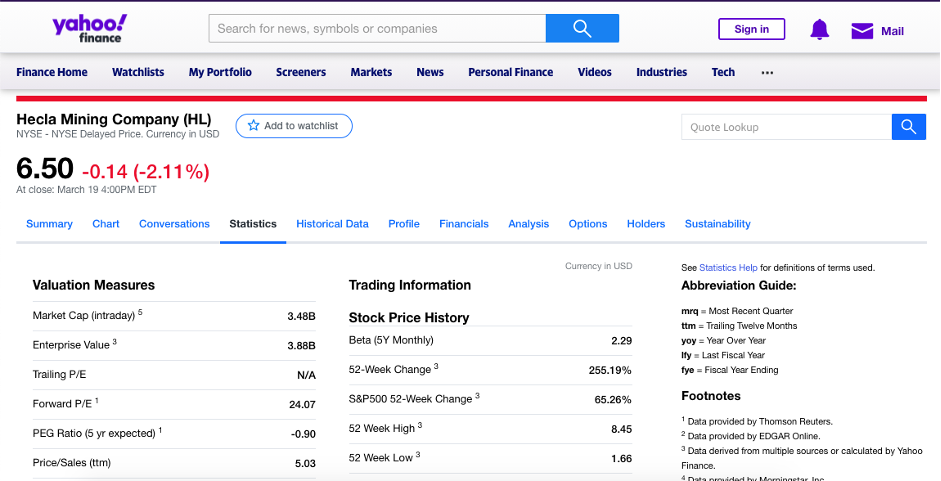
We can see that yahoo finance gives us many fundamentals under the onglet statistics such as market cap, enterprise value, forward P/E, share % Held by Insiders, Quarterly Revenue Growth and many others.
We will extract these informations and build and a database which groups Hecla mining fundamentals.
Let’s import the libraries needed for our tasks:
from bs4 import BeautifulSoup import requests import pandas as pd
Now, we Send an HTTP request to the URL of the statistics webpage of Hecla Mining: https://finance.yahoo.com/quote/HL/key-statistics?p=HL
sec=['HL'] url = 'https://finance.yahoo.com/quote/'+sec+'/key-statistics?p='+sec r = requests.get(url) data = r.text
The server responds to the request by returning the HTML content of the webpage. For this task, we will use a third-party HTTP library for python-requests. Since we have accessed the HTML content, we must parse the data.
Most of the HTML data is nested, we cannot extract data simply through string processing. We need a parser which will create a nested/tree structure of the HTML data. We will use Beautifulsoup default parser.
soup = BeautifulSoup(data, features="html.parser")
A Beautifulsoup object is created by passing two arguments:
data: Hecla mining fundamentals web page raw HTML content.
html.parser: The HTML parser we want to use on the raw html content.
Now, we want to extract the useful data from the HTML content. The soup object contains the nested structure which could be extracted by filtering using find_all() method which returns a list of all matching elements.
The proper filtering element could be fetched from inspecting the html element using the browser developer tools.
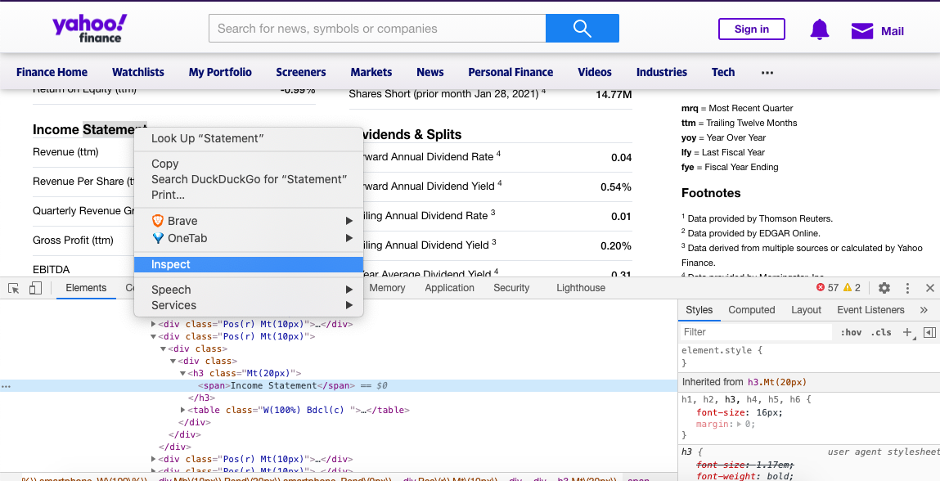
Each quote of the filtered elements is iterated using a variable called row. We create two lists: parameters and val where we store the fundamental name and its corresponding value.
rows=soup.find_all('td')
parameters=[]
val=[]
for row in rows[::2]:
parameters.append(row.get_text(',').split(',')[0])
for row in rows[1::2]:
val.append(row.get_text(',').split(',')[0])
We just accessed the nested structure using dot notation. In order to access the text inside an HTML element, we have use .text.
We now save our data in a pandas dataframe built from the previous lists:
df=pd.DataFrame(index=parameters,columns=[sec]) df[sec]=val df.index.name='Asset' df=df.transpose()
The final built dataframe contains 59 columns of fundamentals of Hecla Mining Company:

4. Build stocks fundamentals database of any desired company
So, this was an example of how to get fundamentals of Hecla Mining from Yahoo Finance. From here, you can try to get fundamentals of any company you wish to analyze from its ticker symbol. In case of many companies, you can loop on the code shared previously and get a pandas dataframe of fundamentals, for example: getting Walmart, Tesla, Pfizer and Zillow fundamentals following the same logic gives the following:
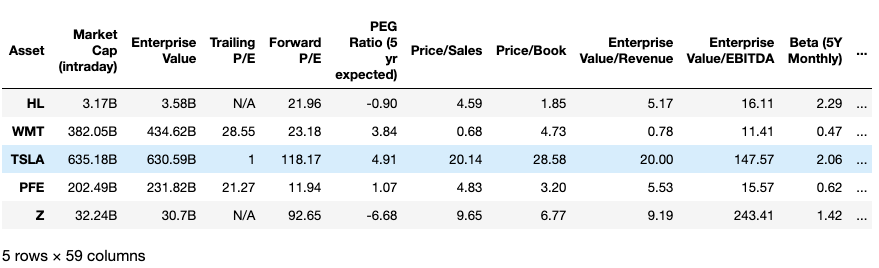
We hope this interactive article from yacodata at www.yacodata.com helped you understand the basics getting stocks fundamentals from yahoo finance.
If you liked this article and this blog, tell us about it our comment section. We would love to hear your feedback!